MAT软件使用入门 #
MAT(Memory Analyzer Tool)工具是一款功能强大的Java堆内存分析器。可以用子查找内存泄漏以及查看内存消耗情况
MAT是基于Eclipse开发的,不仅可以单独使用,还可以作为插件的形式嵌入在Eclipse中使用。是一款免费的性能分析工具,使用起来非常方便。大家可以在 [https://www.eclipse.org/mat/downloads.php] 进行下载
只要确保机器上装有JDK并配置好相关的环境变量,MAT就可以正常启动
MAT不是一个万能工具,它并不能处理所有类型的堆存储文件。但是比较主流的厂家和格式,例如Sun, HP,SAP 所采用的 HPROF 二进制堆存储文件,以及IBM 的 PHD 堆存储文件等都能被很好地解析 MAT最吸引人的还是能够快速为开发人员生成内存泄漏报表,方便定位问题和分析问题。虽然MAT有如此强大的功能,但是内存分析也没有简单到一键完成的程度,很多内存问题还是需要我们从MAT展现给我们的信息当中通过经验和直觉来判断才能发现
MAT帮助文档查看(下面【参考文献】中有中文文档,有需要也可以自行下载)

获取堆dump文件 #
MAT可以分析堆dump文件,在进行内存分析时,只要获得了反映当前JVM进程内存映像的hprof文件,通过MAT打开就可以直观地查看内存信息
一般说来,这些内存信息包含:
- 所有的对象信息,包括对象实例、成员变量、存储于栈中的基本类型值和存储于堆中的其他对象的引用值
- 所有的类信息,包括classloader、类名称、父类、静态变量等
- GCRoot到所有的这些对象的引用路径
- 线程信息,包括线程的调用栈及此线程的线程局部变量(TLS)
获取堆dump文件有两种方式:
1、手动生成:jmap命令生成,可以生成任意一个java进程的dump文件 2、自动生成:通过配置JVM参数生成
手动生成 #
使用jmap指令生成dump文件的操作算得上是最常用的jmap命令之一,将堆中所有存活对象导出至一个文件之中
jmap官方帮助文档:
[https://docs.oracle.com/javase/8/docs/technotes/tools/unix/jmap.html]
生成命令:
jmap -dump:format=b,file=<filename.hprof> <pid>
jmap -dump:live,format=b,file=<filename.hprof> <pid>
说明:
guoyanfei@guoyanfeideiMac:~|⇒ jmap -help
Usage:
jmap [option] <pid>
(连接到正在运行的进程)
jmap [option] <executable <core>
(连接到核心文件)
jmap [option] [server_id@]<remote server IP or hostname>
(连接到远程调试服务器)
其中 <option> 是以下之一:
<none> 打印与 Solaris pmap 相同的信息
-heap 打印 java 堆摘要
-histo[:live] 打印java对象堆的直方图; 如果指定了 "live" 子选项,只计算活动对象
...
-dump:<dump-options> 以 hprof 二进制格式转储 java 堆
dump-options:
live dump活动的对象; 如果没有指定live,会dump堆中所有的对象
format=b 二进制格式
file=<file> 把堆dump到一个文件<file>
示例: jmap -dump:live,format=b,file=heap.hprof <pid>
...
注意:
由于jmap将访问堆中的所有对象,为了保证在此过程中不被应用线程干扰,jmap需要借助安全点机制,让所有线程停留在不改变堆中数据的状态。也就是说,由jmap导出的堆快照必定是安全点位置的。这可能导致基于该堆快照的分析结果存在偏差
举个例子,假设在编译生成的机器码中,某些对象的生命周期在两个安全点之间,那么 :live 选项将无法探知到这些对象
另外,如果某个线程长时间无法跑到安全点,jmap将一直等下去
通过jmap生成dump文件,会引起STW(Stop The World),所以在jmap之前应该先保证此操作不影响正常的生产,一般需要先停止该机器接收生产流量,部分场景必须要有流量才能生成有效的dump文件的话,务必要评估清楚后果,才可以执行
自动生成 #
当程序发生OOM退出系统时,一些瞬时信息都随着程序的终止而消失,而重现OOM问题往往比较困难或者耗时。此时若能在OOM时,自动导出dump文件就显得非常迫切
JVM启动参数加上:-XX:+HeapDumpOnOutOfMemoryError 和 -XX:HeapDumpPath=path(dump文件存储路径) 两个参数,可以在程序发生OOM的时候,导出应用程序的当前堆快照
自动生成dump文件,会在写dump文件之前触发一次Full GC,所以产生的dump文件里保存的都是Full GC后留下的信息 手动生成dump文件,如果不加:live,在生成前不会自动触发Full GC,加了:live,才会触发Full GC
打开堆dump文件(本文在macOS中进行) #
将上一步生成的dump文件,下载到本地
在打开MAT软件之前,需要对软件的JVM启动参数进行修改(调大软件的运行内存)(否则可能无法正常打开dump文件)
修改配置文件: [ MemoryAnalyzer.ini ]
路径: /Applications/mat.app/Contents/Eclipse/MemoryAnalyzer.ini
参数: -Xms8192m -Xmx8192m (根据自身电脑配置进行设置)
设置完成,打开MAT软件执行如下操作
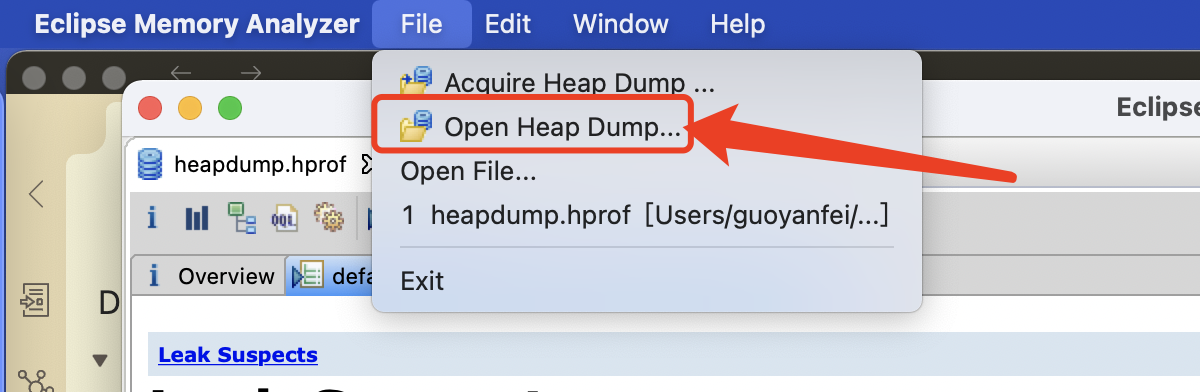
点击菜单栏 File -> Open Heap Dump… -> 选择本地目录中已准备好的dump文件 -> 打开
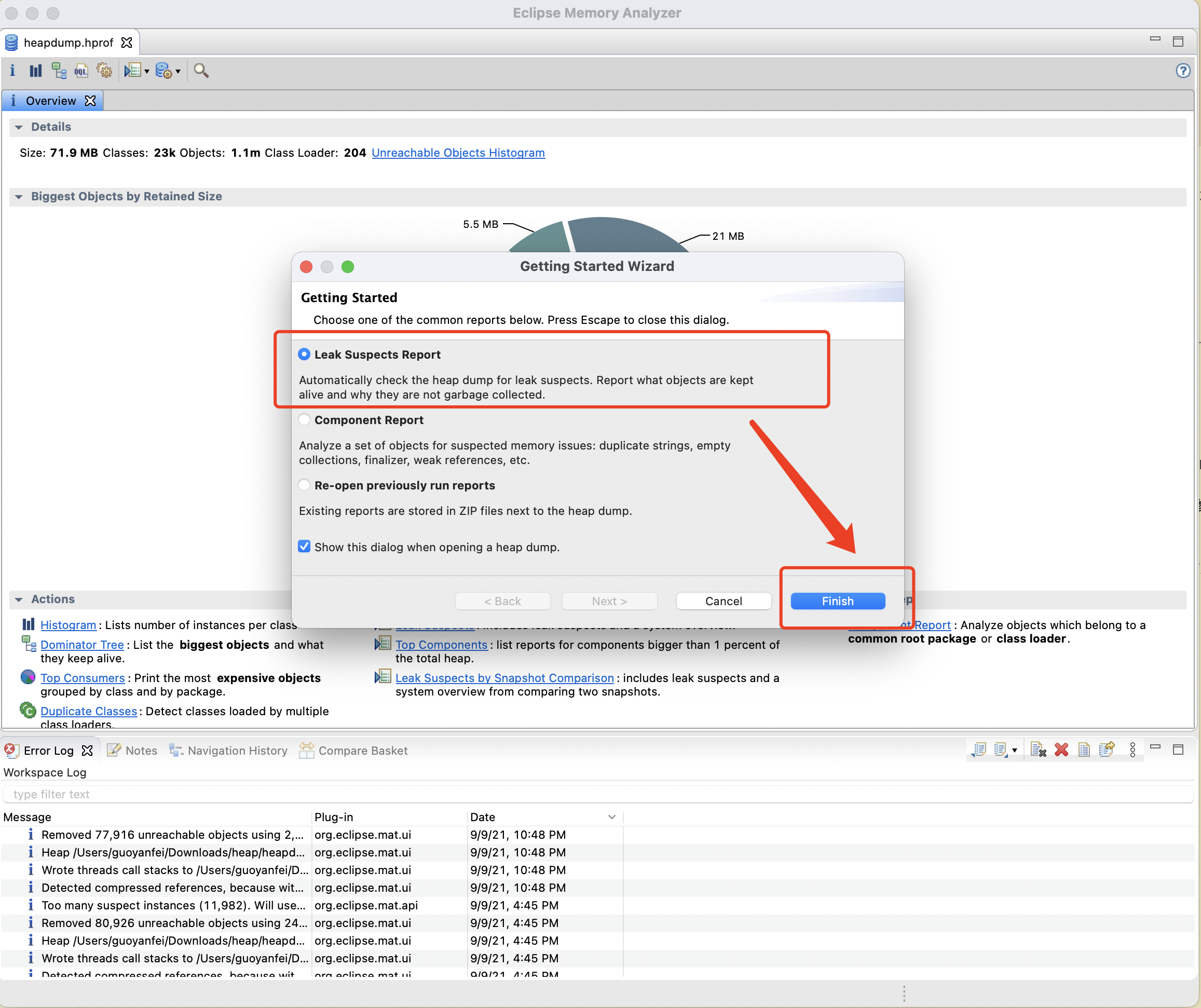
选择 Leak Suspects Report(内存泄露报告) -> Finish 成功打开报告,即可进行后续的分析
MAT功能介绍 #
Histogram #
展示了各个类的实例数目以及这些实例的Shallow heap或者Retained heap的总和
thread_overview #
详细地展示线程信息,包括局部变量占用的内存等
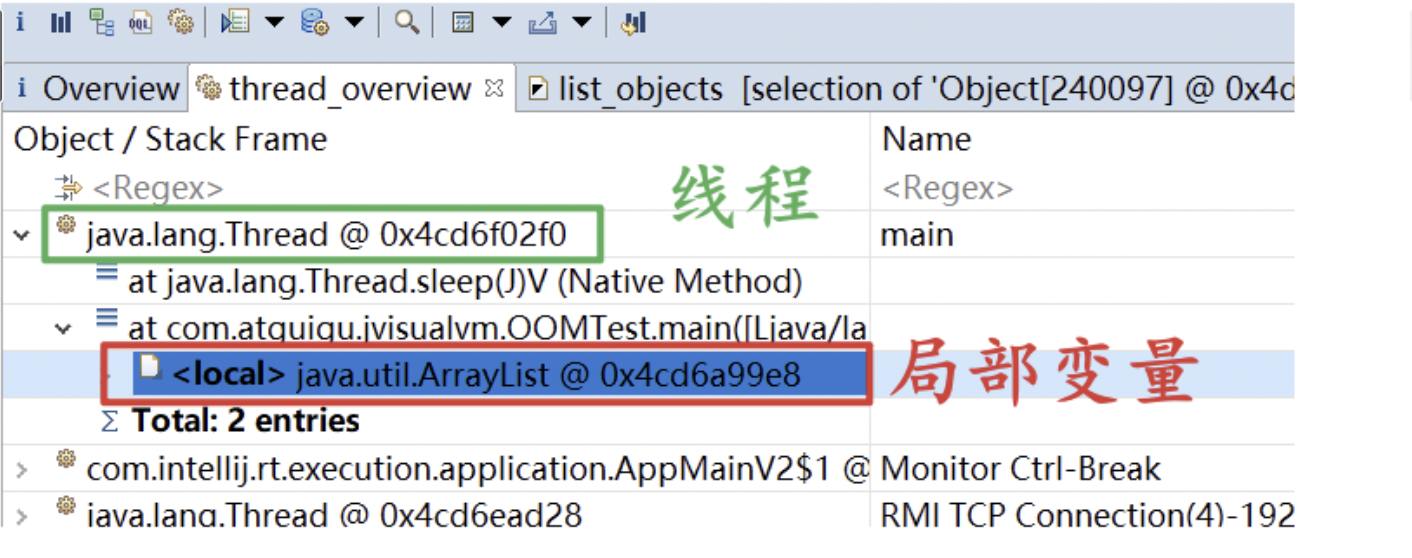
获得对象互相引用的关系 #

浅堆与深堆 #
浅堆(Shallow Heap) #
浅堆(Shallow Heap)是指一个对象所消耗的内存(指这个对象它自己占了多少内存)
深堆(Retained Heap) #
- 保留集(Retained Set):
对象A的保留集指当对象A被垃圾回收后,可以被释放的所有的对象集合(包括对象A本身),即对象A的保留集可以被认为是只能通过对象A被直接或间接访问到的所有对象的集合。通俗地说,就是指仅被对象A所持有的对象的集合
- 深堆(Retained Heap):
深堆是指对象的保留集中所有的对象的浅堆大小之和
注意:浅堆指对象本身占用的内存,不包括其内部引用对象的大小。一个对象的深堆只能通过该对象访问到的(直接或间接)所有对象的浅堆之和,即对象被回收后,可以释放的真实空间
当前深堆大小 = 当前对象的浅堆大小 + 对象中所包含对象的深堆大小
补充:对象实际大小 #
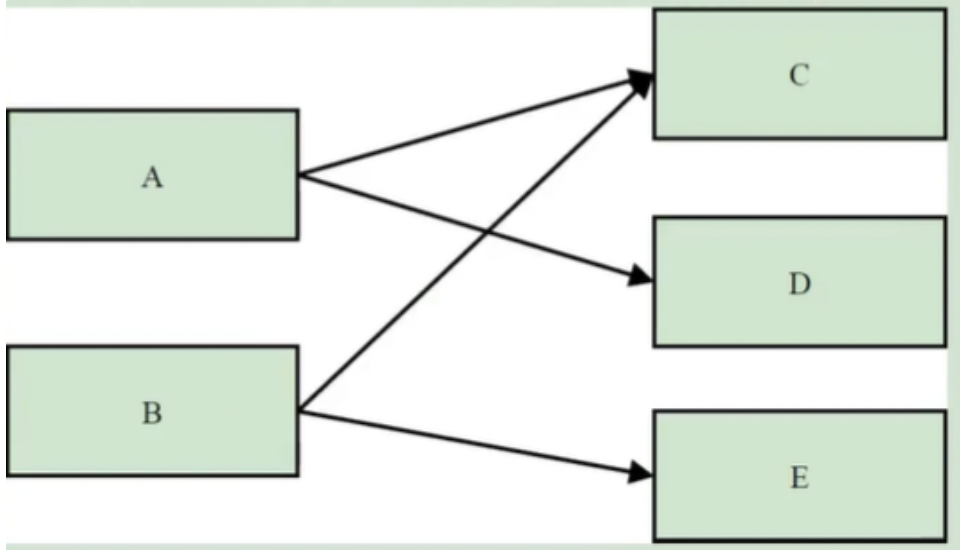
另外一个常用的概念是对象的实际大小。这里,对象的实际大小定义为一个对象所能触及的所有对象的浅堆大小之和,也就是通常意义上我们说的对象大小。与深堆相比,似乎这个在日常开发中更为直观和被人接受,但实际上,这个概念和垃圾回收无关
下图显示了一个简单的对象引用关系图,对象A引用了C和D,对象B引用了C和E。那么对象A的浅堆大小只是A本身,不含C和D,而A的实际大小为A、C、D三者之和。而A的深堆大小为A与D之和,由于对象C还可以通过对象B访问到,因此不在对象A的深堆范围内
支配树(Dominator Tree) #
支配树的概念源自图论
MAT提供了一个称为支配树(Dominator Tree)的对象图。支配树体现了对象实例间的支配关系。在对象引用图中,所有指向对象B的路径都经过对象A,则认为对象A支配对象B。如果对象A是离对象B最 近的一个支配对象,则认为对象A为对象B的直接支配者。支配树是基于对象间的引用图所建立的,它有以下基本性质:
- 对象A的子树(所有被对象A支配的对象集合)表示对象A的保留集 (retained set),即深堆
- 如果对象A支配对象B,那么对象A的直接支配者也支配对象B
- 支配树的边与对象引用图的边不直接对应
如下图所示:左图表示对象引用图,右图表示左图所对应的支配树。对象A和B由根对象直接支配,由于在到对象C的路径中,可以经过A,也可以经过B,因此对象C的直接支配者也是根对象。对象F与对象D相互引用,因为到对象F的所有路径必然经过对象D,因此,对象D是对象F的直接支配者。而到对象D的所有路径中,必然经过对象C,即使是从对象F到对象D的引用,从根节点出发,也是经过对象C的,所以,对象D的直接支配者为对象C
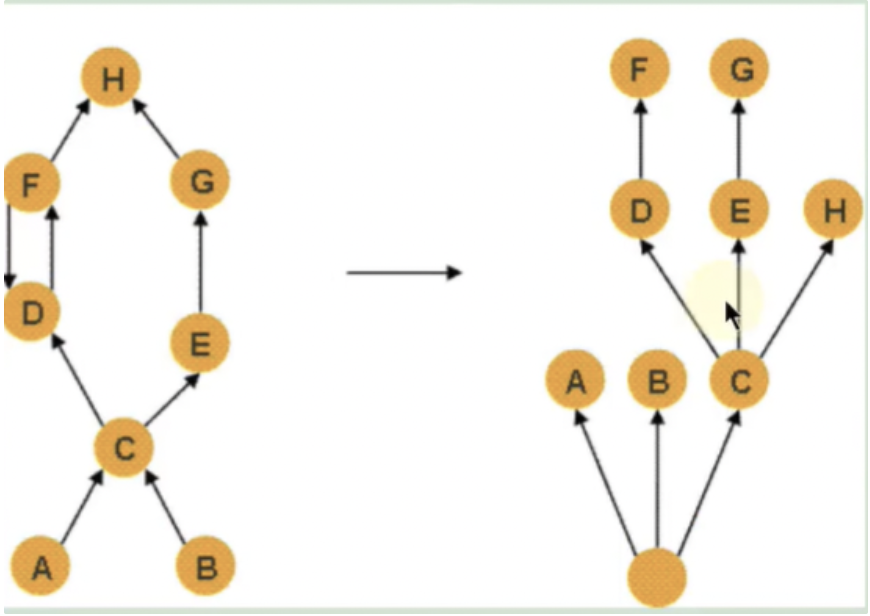
同理,对象E支配对象G。到达对象H的可以通过对象D,也可以通过对象E,因此对象D和E都不能支配对象H,而经过对象C既可以到达D也可以到达E,因此对象C为对象H的直接支配者
在MAT工具中如何查看支配树 #
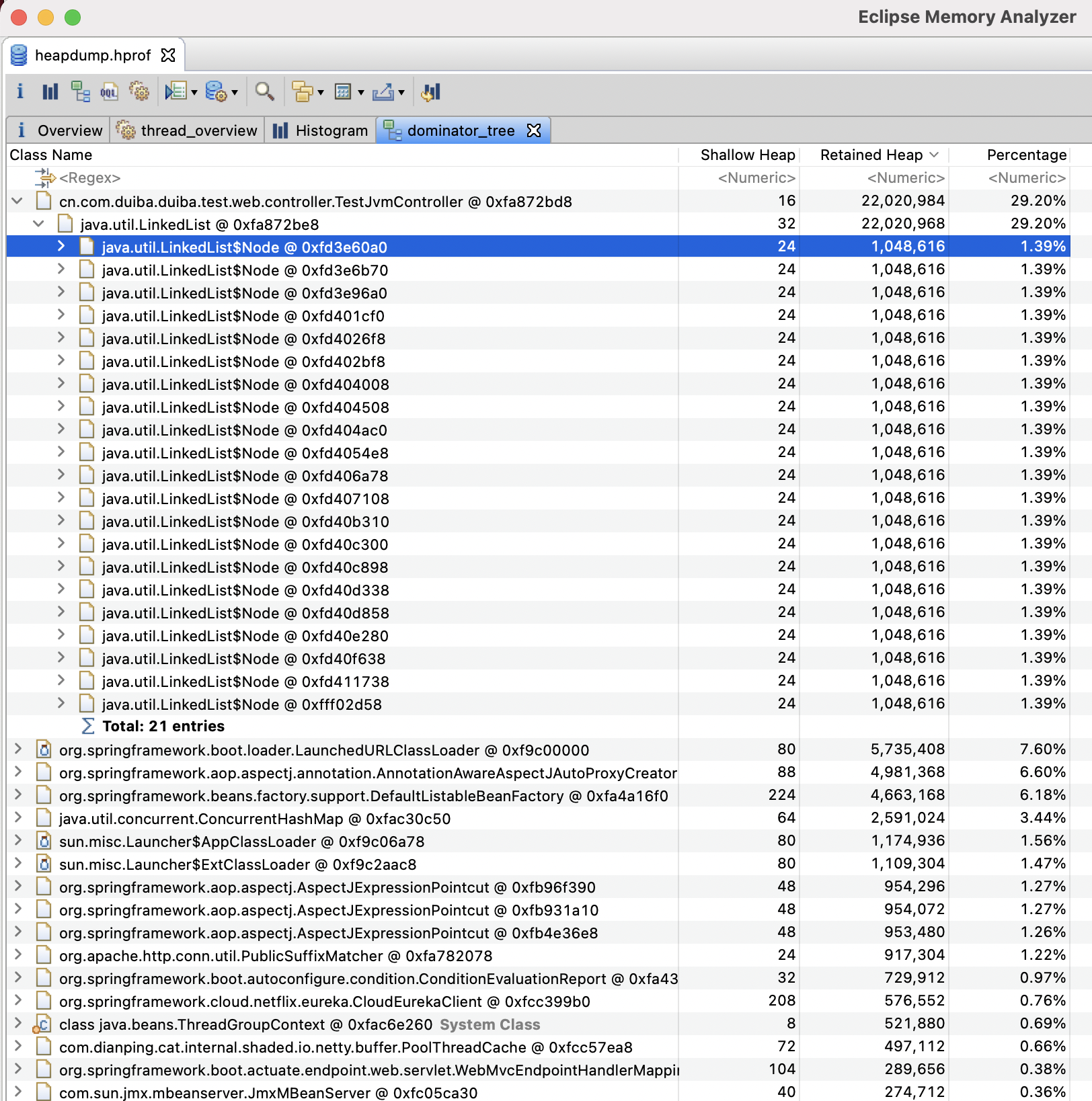
在MAT中,单击工具栏上的对象支配树按钮,可以打开对象支配树视图
使用OQL语言查询对象信息 #
MAT支持一种类似于SQL的查询语言OQL (Object Query Language)。OQL使用类SQL语法,可以在堆中进行对象的查找和筛选
例子:
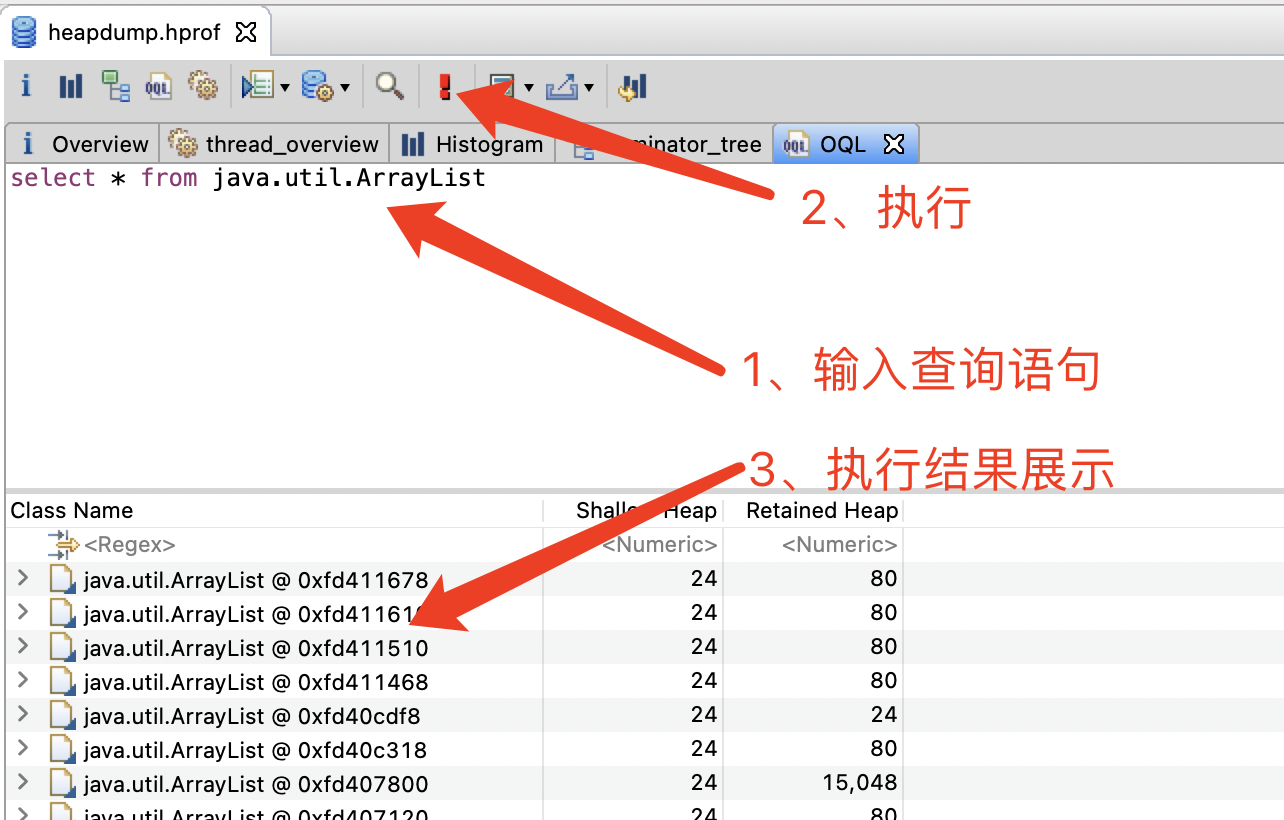
select * from java.util.ArrayList (列出所有的ArrayList对象信息)
select v.elementData from java.util.ArrayList v (注意:elementData代表ArrayList中的数组,结果最终以数组形式将结果呈现出来)
select objects v.elementData from java.util.ArrayList v (注意:elementData代表ArrayList中的数组,objects代表对象类型,所以最终以对象形式将结果呈现出来,同时展示出来的还有浅堆、深堆)
select as retained set * from cn.com.duiba.duiba.test.web.controller.TestJvmController (得到对象的保留集)
select * from char[] s where s.@length > 10 (char型数组长度大于10的数组)
select * from java.lang.String s where s.value != null (字符串值不为空的字符串信息)
select toString(f.path.value) from java.io.File f (列出文件的路径值)
SELECT v.elementData.@length FROM java.util.ArrayList v (列出Arraylist对象中ArrayList中的数组长度)
更多的OQL语法,请查看文档,如下方式可进行文档的查看(此页面通过 Help -> Help Contents 进入)
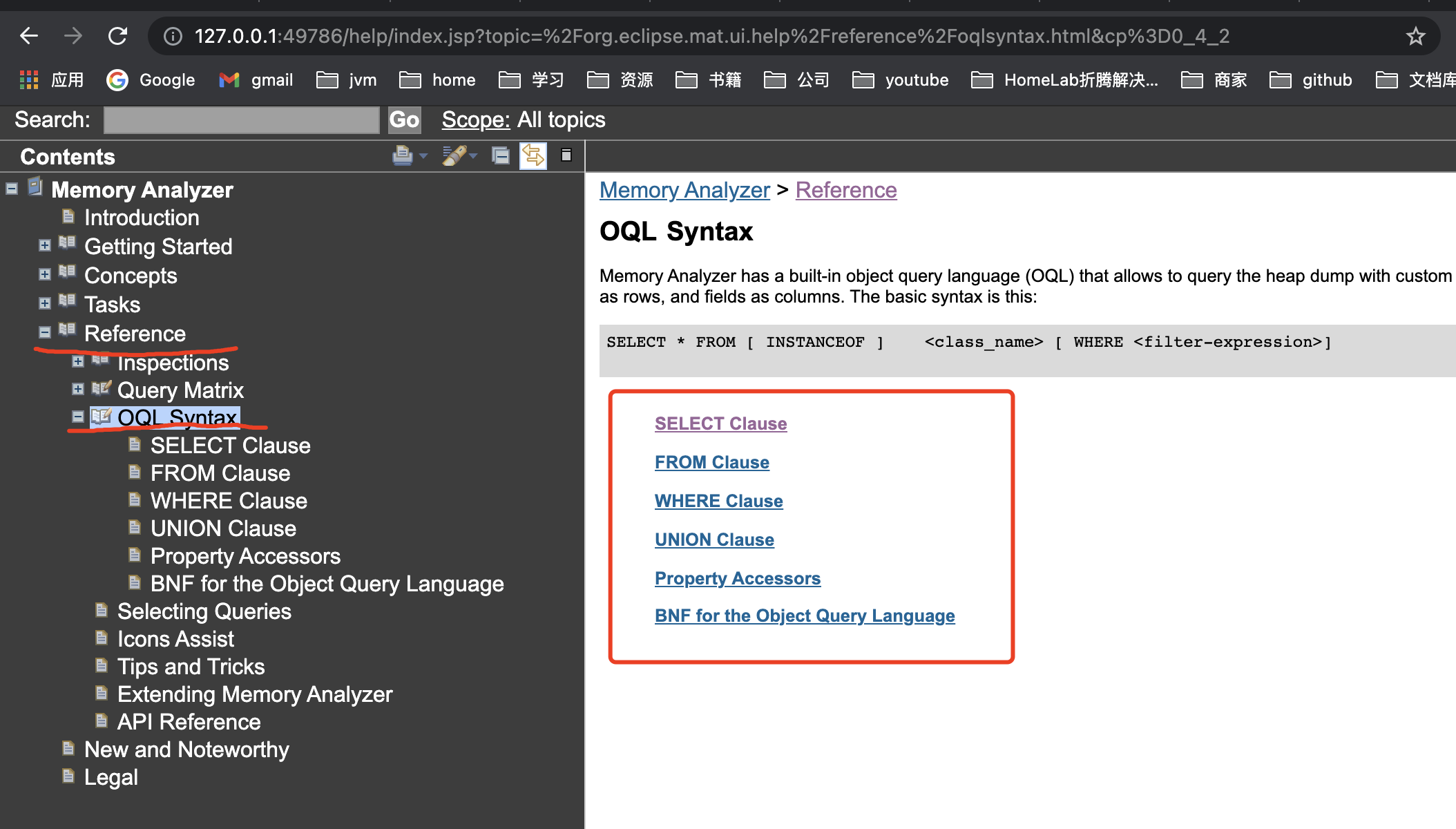
简单案例 #
测试代码:
/**
* -Xmx100m -Xms100m -XX:MetaspaceSize=64m -XX:MaxMetaspaceSize=128m -Xss256k
* -XX:+UseG1GC
* -XX:SurvivorRatio=8
* -XX:MaxGCPauseMillis=200
* -XX:G1ReservePercent=10
* -XX:InitiatingHeapOccupancyPercent=40
* -XX:ParallelGCThreads=8
* -Xloggc:/Users/guoyanfei/logs/shm/gc.log
* -XX:+PrintGCApplicationStoppedTime
* -XX:+PrintGCDateStamps
* -XX:+PrintGCDetails
* -XX:+PrintCodeCache
* -XX:+UseGCLogFileRotation
* -XX:NumberOfGCLogFiles=2
* -XX:GCLogFileSize=10m
* -XX:+HeapDumpOnOutOfMemoryError
* -XX:HeapDumpPath=/Users/guoyanfei/logs/
* -XX:MaxDirectMemorySize=50M
* Created by guoyanfei .
* 2021/9/6 .
*/
@RestController
@RequestMapping("/test/jvm")
public class TestJvmController {
private Queue<byte[]> bss = new LinkedList<>();
/**
* 每个1秒往bss的queue中加入1M数据,该数据无法被垃圾回收
* 超过20M后,开始出队列,模拟一直FGC的情况
* @return
*/
@SneakyThrows
@GetMapping("/cpu")
public String cpu() {
int i = 0;
while (true) {
Thread.sleep(10);
if (i++ > 20) {
bss.poll();
}
byte[] bs = new byte[1 * 1024 * 1024];
bss.add(bs);
}
}
}
以上测试代码,在部署完成后,访问此Controller接口,可以发现CPU飙升,通过[[Java应用CPU使用率高一般排查思路(centos)]]进行排查,可以发现JVM一直在进行FGC,然后dump堆快照,通过MAT进行排查
观察 Histogram ,可以发现byte[]的 Retained Heap >= 23729680 Byte = 22.63MB,而JVM的堆内存总大小只有100MB,所以考虑byte[]存在问题
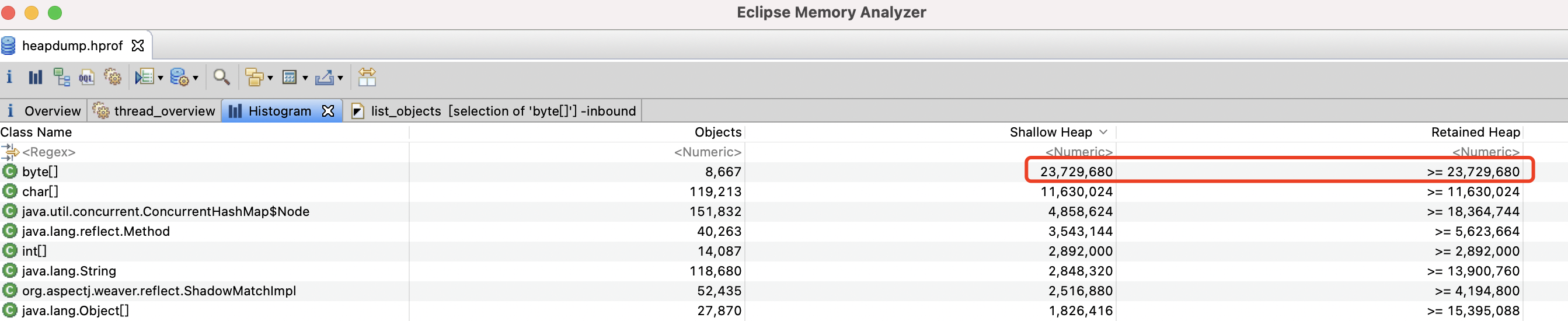
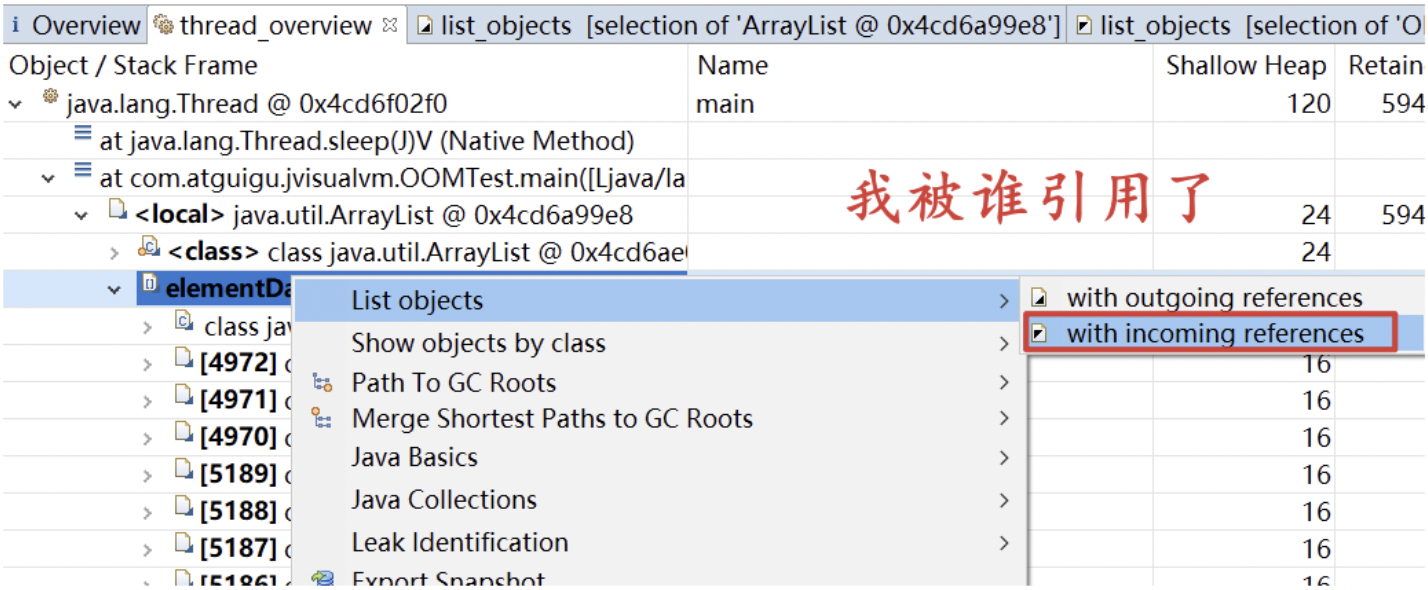
右键点击 byte[] -> List objects -> with incoming references (谁引用了我)
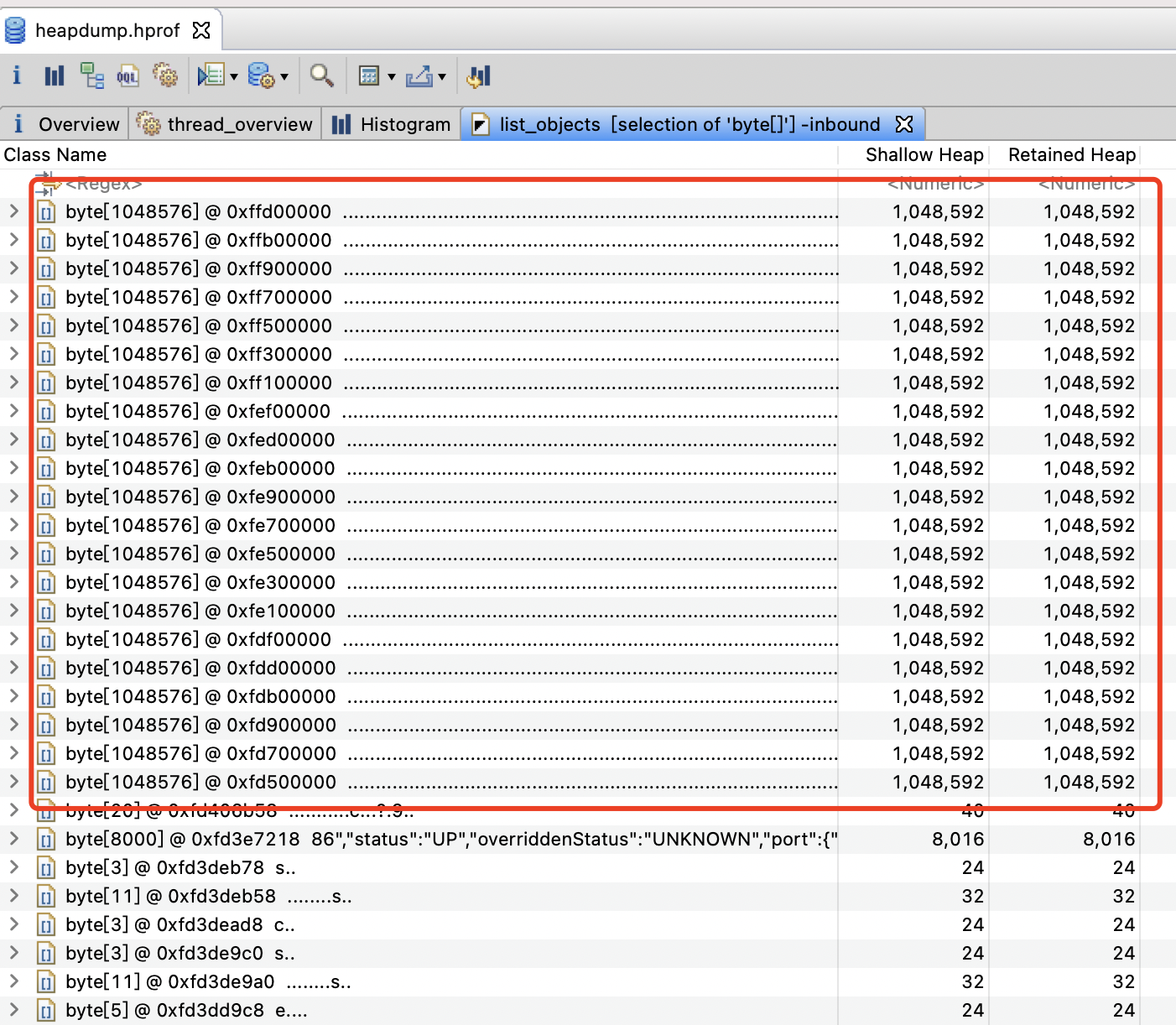
可以看到有一堆(20多个)1MB大小的byte[]对象,而这些对象无法被回收,一般都会有GC Roots可以触达这些对象,所以我们需要找到这些对象到GC Roots的路径,选择任意一个右键 Path To GC Roots -> with all references
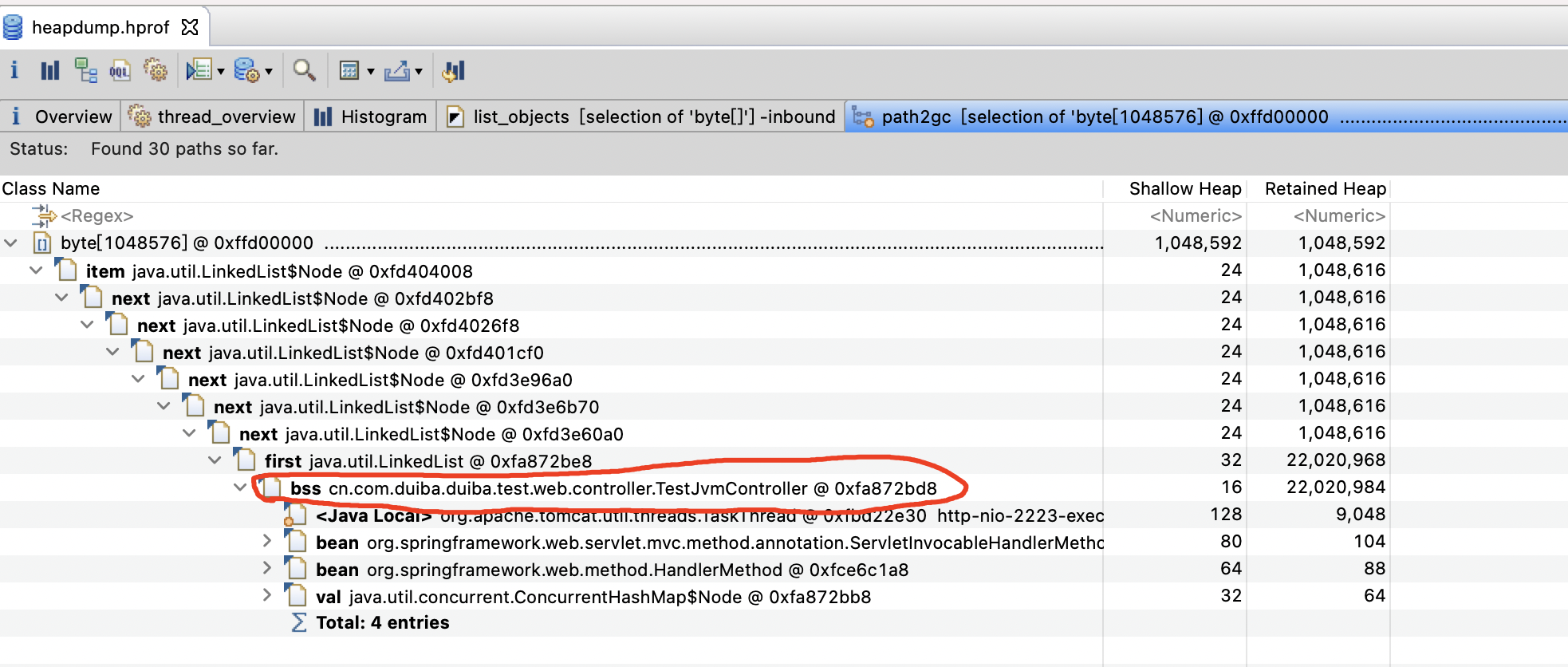
可以发现,cn.com.duiba.duiba.test.web.controller.TestJvmController bss对象,是我们自己写的代码,再简单看下代码实现,即可发现问题所在
以上只是一种排查方式,其实使用支配树视图,可以更加清晰明了地发现该问题: